
性能测试报告
测试说明
a、本次性能测试,测试了dubbo2.0所有支持的协议在不同大小和数据类型下的表现,并与dubbo1.0进行了对比。
b、整体性能相比1.0有了提升,平均提升10%,使用dubbo2.0新增的dubbo序列化还能获得10%~50%的性能提升,详见下面的性能数据。
c、稳定性测试中由于将底层通信框架从mina换成netty,old区对象的增长大大减少,50小时运行,增长不到200m,无fullgc。(可以确认为mina在高并发下的设计缺陷)
d、存在的问题:在50k数据的时候2.0性能不如1.0,怀疑可能是缓冲区设置的问题,下版本会进一步确认。
测试环境
2.1 硬件部署与参数调整
主机/ip
硬件配置
操作系统及参数调整
| 10.20.153.11 | 机型 | Tecal BH620 | |
| CPU | model name : Intel(R) Xeon(R) CPU E5520 @ 2.27GHz cache size : 8192 KB processor_count : 16 | ||
| 内存 | Total System Memory: 6G Hardware Memory Info: Size: 4096MB, 1066MHz(0.9ns) Size: NoModule, Unknown Size: 4096MB, 1066MHz(0.9ns) Size: NoModule, Unknown Size: 4096MB, 1066MHz(0.9ns) Size: NoModule, Unknown Size: 4096MB, 1066MHz(0.9ns) Size: NoModule, Unknown Size: 4096MB, 1066MHz(0.9ns) Size: NoModule, Unknown Size: 4096MB, 1066MHz(0.9ns) Size: NoModule, Unknown | ||
| 网络 | Total System Memory: 6G Hardware Memory Info: Size: 4096MB, 1066MHz(0.9ns) Size: NoModule, Unknown Size: 4096MB, 1066MHz(0.9ns) Size: NoModule, Unknown Size: 4096MB, 1066MHz(0.9ns) Size: NoModule, Unknown Size: 4096MB, 1066MHz(0.9ns) Size: NoModule, Unknown Size: 4096MB, 1066MHz(0.9ns) Size: NoModule, Unknown Size: 4096MB, 1066MHz(0.9ns) Size: NoModule, Unknown | ||
| 磁盘 | /dev/sda: 597.9 GB, | 2.6.18-128.el5xen x86_64 | |
| 10.20.153.10 | 机型 | Tecal BH620 | |
| CPU | model name : Intel(R) Xeon(R) CPU E5520 @ 2.27GHz cache size : 8192 KB processor_count : 16 | ||
| 内存 | Total System Memory: 6G Hardware Memory Info: Size: 4096MB, 1066MHz(0.9ns) Size: NoModule, Unknown Size: 4096MB, 1066MHz(0.9ns) Size: NoModule, Unknown Size: 4096MB, 1066MHz(0.9ns) Size: NoModule, Unknown Size: 4096MB, 1066MHz(0.9ns) Size: NoModule, Unknown Size: 4096MB, 1066MHz(0.9ns) Size: NoModule, Unknown Size: 4096MB, 1066MHz(0.9ns) Size: NoModule, Unknown | ||
| 网络 | eth0: Link is up at 1000 Mbps, full duplex. peth0: Link is up at 1000 Mbps, full duplex. | ||
| 磁盘 | /dev/sda: 597.9 GB, | 2.6.18-128.el5xen x86_64 |
2.2 软件架构
主机/ip
软件名称及版本
关键参数
| java version "1.6.0_18" Java(TM) SE Runtime Environment (build 1.6.0_18-b07) Java HotSpot(TM) 64-Bit Server VM (build 16.0-b13, mixed mode) | -server -Xmx2g -Xms2g -Xmn256m -XX:PermSize=128m -Xss256k -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 | |
| jboss-4.0.5.GA | ||
| httpd-2.0.61 | KeepAlive On MaxKeepAliveRequests 100000 KeepAliveTimeout 180 MaxRequestsPerChild 1000000 <IfModule worker.c> StartServers 5 MaxClients 1024 MinSpareThreads 25 MaxSpareThreads 75 ThreadsPerChild 64 ThreadLimit 128 ServerLimit 16 </IfModule> |
测试目的
3.1 期望性能指标(量化)
场景名称
对应指标名称
期望值范围
实际值
是否满足期望(是/否)
| 1k数据 |
响应时间 |
0.9ms |
0.79ms |
是 |
| 1k数据 |
TPS |
10000 |
11994 |
是 |
3.2 期望运行状况(非量化,可选)
2.0性能不低于1.0,2.0和1.0互调用的性能无明显下降。 除了50k string其余皆通过
JVM内存运行稳定,无OOM,堆内存中无不合理的大对象的占用。通过
CPU、内存、网络、磁盘、文件句柄占用平稳。通过
无频繁线程锁,线程数平稳。通过
业务线程负载均衡。通过
测试脚本
1、性能测试场景(10并发)
a、传入1kString,不做任何处理,原样返回
b、传入50kString,不做任何处理,原样返回
c、传入200kString,不做任何处理,原样返回
d、传入1k pojo(嵌套的复杂person对象),不做任何处理,原样返回
上述场景在dubbo1.0\dubbo2.0(hessian2序列化)\dubbo2.0(dubbo序列化)\rmi\hessian3.2.0\http(json序列化)进行10分钟的性能测试。 主要考察序列化和网络IO的性能,因此服务端无任何业务逻辑。取10并发是考虑到http协议在高并发下对CPU的使用率较高可能会先打到瓶颈。
2、并发场景(20并发)
传入1kString,在服务器段循环1w次,每次重新生成一个随机数然后进行拼装。
考察业务线程是否能够分配到每个CPU上。
3、稳定性场景(20并发)
同时调用1个参数为String(5k)方法,1个参数为person对象的方法,1个参数为map(值为3个person)的方法,持续运行50小时。
4、高压力场景(20并发)
在稳定性场景的基础上,将提供者和消费者布置成均为2台(一台机器2个实例),且String的参数从20byte到200k,每隔10分钟随机变换。
测试结果
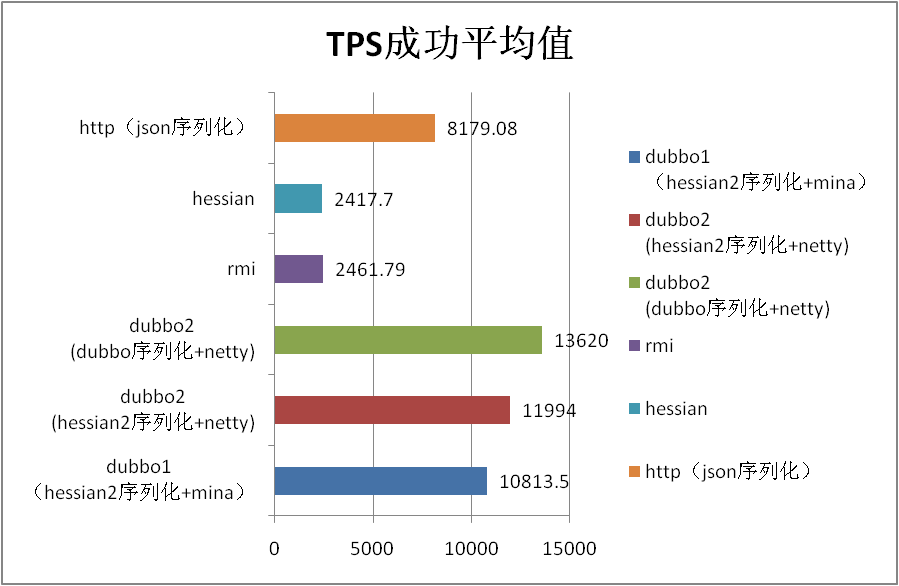
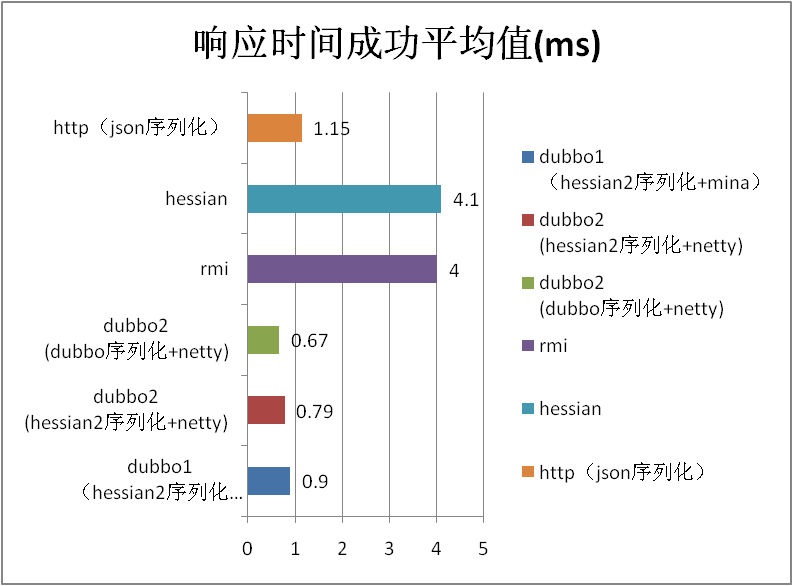
5.1 场景名称:pojo 场景
| TPS成功平均值 |
响应时间成功平均值(ms) |
|
| dubbo1 (hessian2序列化+mina) |
10813.5 |
0.9 |
| dubbo2 (hessian2序列化+netty) |
11994 |
0.79 |
| dubbo2 (dubbo序列化+netty) |
13620 |
0.67 |
| rmi |
2461.79 |
4 |
| hessian |
2417.7 |
4.1 |
| http(json序列化) |
8179.08 |
1.15 |
| 2.0和1.0默认 对比百分比 |
10.92 |
-12.22 |
| dubbo序列化相比hessian2序列化百分比 |
13.56 |
-15.19 |
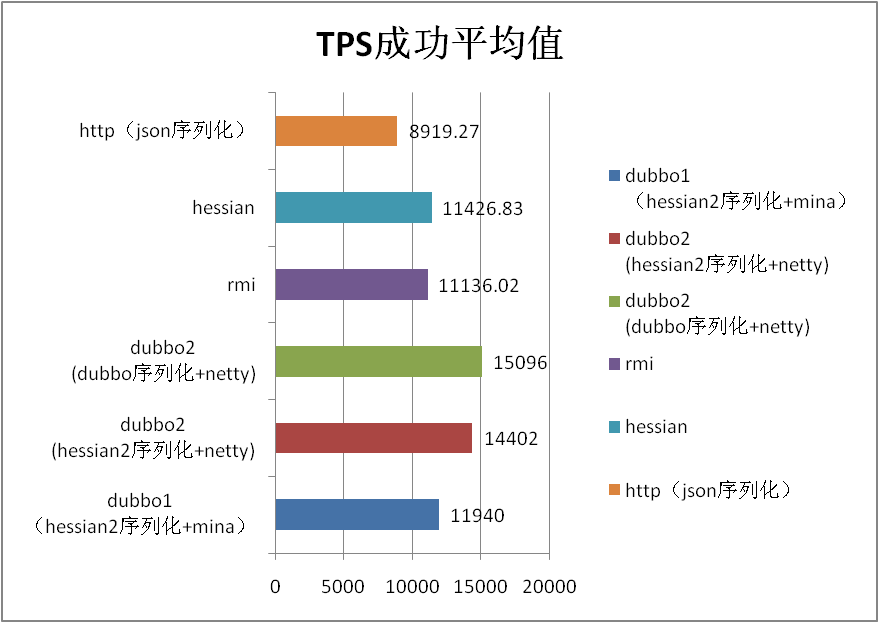
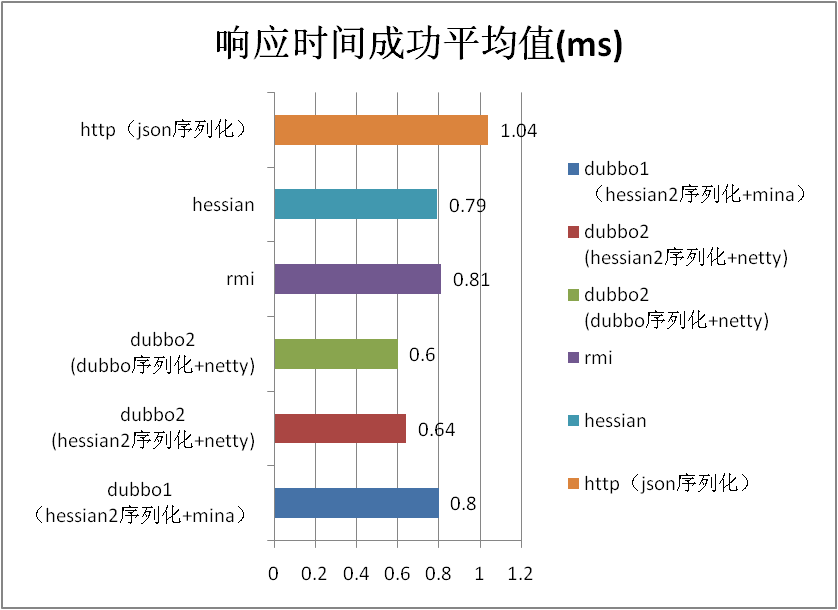
5.2 场景名称:1k string 场景 |
| |
TPS成功平均值 |
响应时间成功平均值(ms) |
| dubbo1 (hessian2序列化+mina) |
11940 |
0.8 |
| dubbo2 (hessian2序列化+netty) |
14402 |
0.64 |
| dubbo2 (dubbo序列化+netty) |
15096 |
0.6 |
| rmi |
11136.02 |
0.81 |
| hessian |
11426.83 |
0.79 |
| http(json序列化) |
8919.27 |
1.04 |
| 2.0和1.0默认 对比百分比 |
20.62 |
-20.00 |
| dubbo序列化相比hessian2序列化百分比 |
4.82 |
-6.25 |
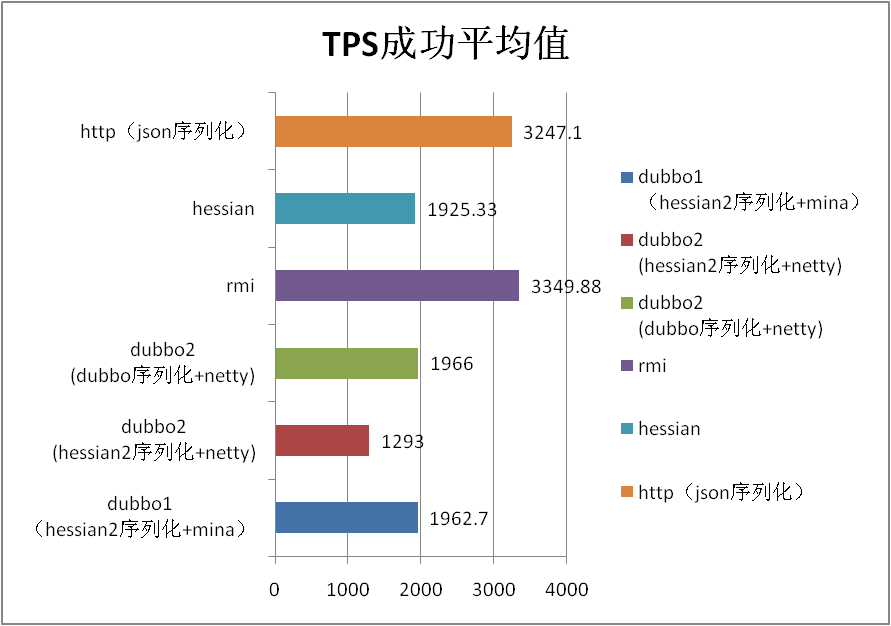
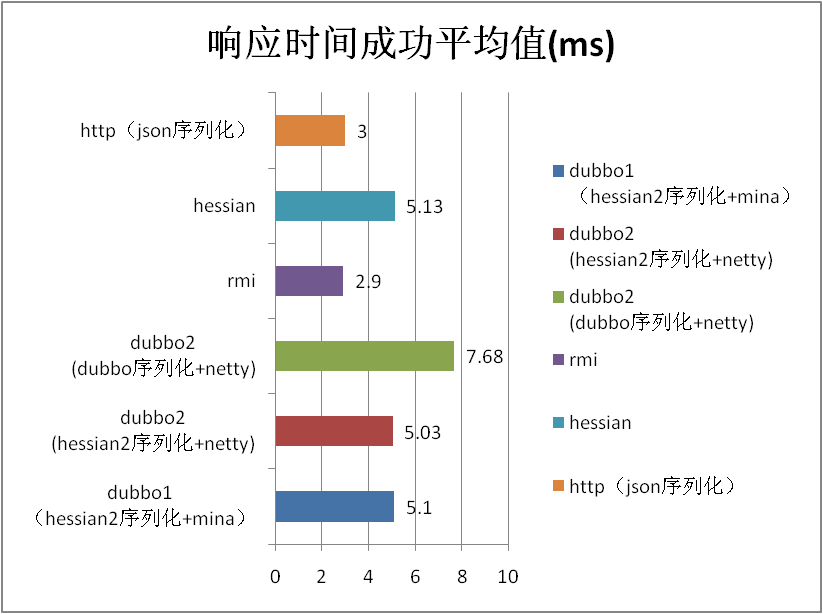
5.3 场景名称:50k string场景 |
| |
TPS成功平均值 |
响应时间成功平均值(ms) |
| dubbo1 (hessian2序列化+mina) |
1962.7 |
5.1 |
| dubbo2 (hessian2序列化+netty) |
1293 |
5.03 |
| dubbo2 (dubbo序列化+netty) |
1966 |
7.68 |
| rmi |
3349.88 |
2.9 |
| hessian |
1925.33 |
5.13 |
| http(json序列化) |
3247.1 |
3 |
| 2.0和1.0默认 对比百分比 |
-34.12 |
-1.37 |
| dubbo序列化相比hessian2序列化百分比 |
52.05 |
52.68 |
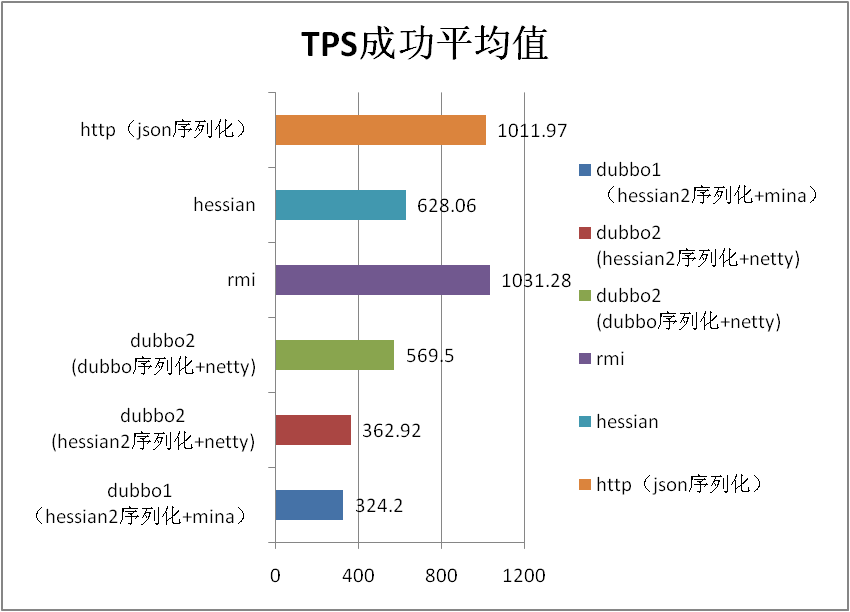
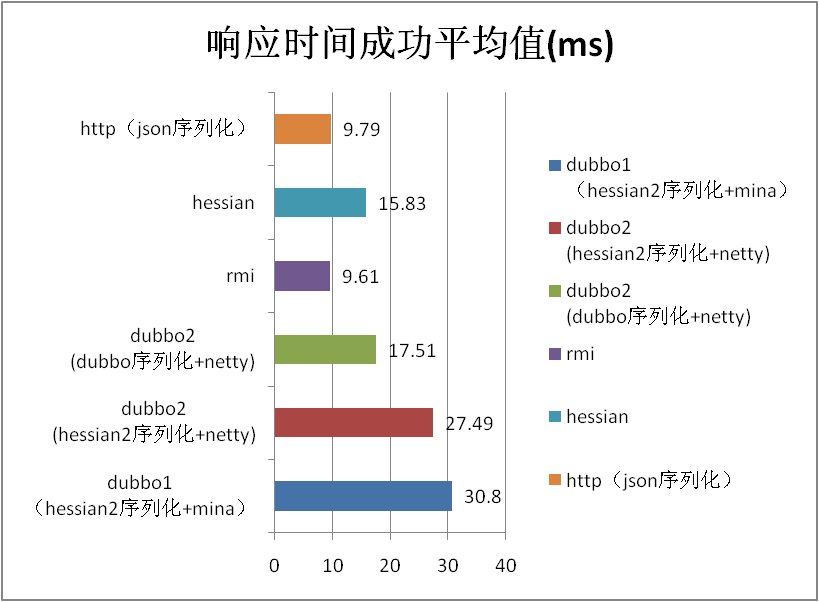
5.4 场景名称:200k string 场景 |
| TPS成功平均值 |
响应时间成功平均值(ms) |
|
| dubbo1 (hessian2序列化+mina) |
324.2 |
30.8 |
| dubbo2 (hessian2序列化+netty) |
362.92 |
27.49 |
| dubbo2 (dubbo序列化+netty) |
569.5 |
17.51 |
| rmi |
1031.28 |
9.61 |
| hessian |
628.06 |
15.83 |
| http(json序列化) |
1011.97 |
9.79 |
| 2.0和1.0默认 对比百分比 |
11.94 |
-10.75 |
| dubbo序列化相比hessian2序列化百分比 |
56.92 |
-36.30 |
测试分析
6.1 性能分析评估
Dubbo2.0的性能测试结论为通过,从性能、内存占用和稳定性上都有了提高和改进。由其是内存管理由于将mina换成netty,大大减少了1.0版本在高并发大数据下的内存大锯齿。如下图:
6.2 性能对比分析(新旧环境、不同数据量级等)
Dubbo2.0相比较Dubbo1.0(默认使用的都是hessian2序列化)性能均有提升(除了50k String),详见第五章的性能数据。
出于兼容性考虑默认的序列化方式和1.0保持一致使用hessian2,如对性能有更高要求可以使用dubbo序列化,由其是在处理复杂对象时,在大数据量下能获得50%的提升(但此时已不建议使用Dubbo协议)。
Dubbo的设计目的是为了满足高并发小数据量的rpc调用,在大数据量下的性能表现并不好,建议使用rmi或http协议。
6.3 测试局限性分析(可选)
本次性能测试考察的是dubbo本身的性能,实际使用过程中的性能有待应用来验证。
由于dubbo本身的性能占用都在毫秒级,占的基数很小,性能提升可能对应用整体的性能变化不大。
由于邮件篇幅所限没有列出所有的监控图,如需获得可在大力神平台上查询。